
PRODUCT
製品紹介
サーバー(ハードウェア)
NVIDIA データセンターGPU製品
データセンター向けアクセラレーテッド
コンピューティング プラットフォーム
NVIDIA™アクセラレーテッド コンピューティング プラットフォームでは、最新のデータセンターにディープラーニング、機械学習、ハイパフォーマンスコンピューティング(HPC)ワークロードを高速化するパワーがもたらされます。

画期的なイノベーション
- Tensorコア
- MIG
- トレーニング高速化
- NVLink
NVIDIA H100 Tensorコア
- 動的に演算を調整することで正確さを維持しながらスループットを加速化
- 多数のAIおよびハイパフォーマンスコンピューティング (HPC) タスクを高速化
- トランスフォーマーネットワークトレーニングを6倍高速化
- すべてのアプリケーションで 3 倍のパフォーマンス向上
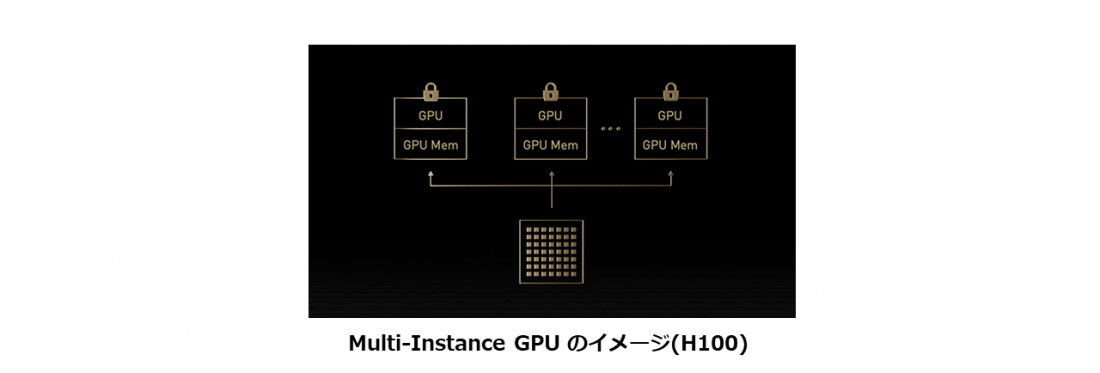
Multi-Instance GPU (MIG)
- GPUを完全に分離された複数の小さなインスタンスに分割
- 各々のGPUにメモリ、キャッシュ、コンピューティングコアを与えます。
- 最大7個のGPUインスタンスで仮想環境のマルチテナント/マルチユーザー構成をサポート
- MIGインスタンスごとに専用のビデオ デコーダーが与えられ、共有インフラストラクチャで安定したハイスループットのインテリジェント ビデオ解析 (IVA) が実現
Transformer Engine
- AIモデルのトレーニングを高速化するように設計されたTransformer Engineとの組み合わせでTensor コアテクノロジを促進
- Hopper TensorコアではFP8とFP16の精度を混在可能
- TransformerのAIコンピュートスピードが劇的に高速化
- Transformer Engine と第4世代 NVIDIA®NVLink®と組み合わせることで Hopper TensorコアはHPCとAIのワークロードを桁違いに高速化
NVLink Switchシステム
- スケールアップに相互接続が可能
- NVLink Switchと組み合わせると、NVLink SwitchシステムはPCIe Gen5の7倍以上の帯域幅でGPUあたり900ギガバイト(GB/s)の双方向で複数サーバーにわたりマルチGPU IOを拡張可能
- 最大256基のH100を接続したクラスターをサポート(前世代のAmpereと比較して約9倍の性能向上)
NVIDIA データセンターGPU製品ご紹介動画
NVIDIA データセンターGPU製品の特長
NVIDIA H100 Tensor コア
Tensorコアは、混合精度のコンピューティングを可能にし、動的に演算を調整することで正確さを維持しながらスループットを加速します。最新世代のTensorコアは、多数のAIおよびハイパフォーマンスコンピューティング (HPC) タスクをこれまで以上に高速化します。トランスフォーマーネットワークトレーニングの6倍の高速化から、すべてのアプリケーションで3倍のパフォーマンス向上まで、NVIDIA Tensorコアは、すべてのワークロードに新しい機能をもたらします。

Multi-Instance GPU (MIG)
Multi-Instance GPU (MIG) は、 A100およびA30のGPUでサポートされている機能であり、ワークロードがGPUを共有することを可能にします。MIGを利用すると、各GPUを複数のGPUインスタンスに分割できます。各インスタンスは完全に分離され、ハードウェアレベルで保護され、専用の高帯域幅メモリ、キャッシュ、コンピューティングコアを与えられます。
Hopper アーキテクチャはMIGの機能をさらに強化し、最大7個のGPUインスタンスで仮想環境のマルチテナント/マルチユーザー構成をサポートします。また、コンフィデンシャルコンピューティングによってハードウェアおよびハイパーバイザーレベルで各インスタンスが分離されるため、非常に安全な構成になっています。MIGインスタンスごとに専用のビデオ デコーダーが与えられ、共有インフラストラクチャで安定したハイスループットのインテリジェントビデオ解析 (IVA) が実現します。そして、Hopperの同時実行MIGプロファイリングを利用することで、管理者はユーザーのために正しいサイズのGPU高速化を監視し、リソース割り当てを最適化できます。
Transformer Engine
NVIDIA Hopperアーキテクチャは、AIモデルのトレーニングを高速化するように設計されたTransformer Engineとの組み合わせで Tensorコアテクノロジを前進させます。Hopper TensorコアではFP8とFP16の精度を混在させることができます。TransformerのAIコンピューティングが劇的に速くなります。Hopper はまた、TF32、FP64、FP16、INT8 の精度の浮動小数点演算 (FLOPS) を前世代に比べ3倍高速化にします。Transformer Engineと第4世代 NVIDIA® NVLink®と組み合わせることでHopper TensorコアはHPCとAIのワークロードを桁違いに高速化します。

NVLink Switch システム
第 4 世代 NVLink は、スケールアップ相互接続です。新しい外部 NVLink Switchと組み合わせると、NVLink Switchシステムは、PCIe Gen5の7倍以上の帯域幅である、GPU あたり 900 ギガバイト/秒 (GB/s) の双方向で複数のサーバーにわたるマルチGPU IO (入出力) を拡張することが可能になりました。NVLink Switch システムは、最大256基のH100を接続したクラスターをサポートし、AmpereでInfiniBand HDRの9倍高い帯域幅を実現します。
さらに、NVLinkはこれまでInfiniBandでのみ利用可能であったSHARPと呼ばれるIn-network Computingをサポートし、57.6テラバイト/秒 (TB/s) の All-to-Allの帯域幅を実現しながら、FP8スパースAIコンピューティングで1 exaFLOPSという驚くべき性能を提供することができるようになりました。

NVIDIA データセンターGPU製品スペック一覧

| H200 SXM1 | H200 NVL1 | |
|---|---|---|
| FP64 | 34 TFLOPS | 30 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS | 60 TFLOPS |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| TF32 Tensor Core2 | 989 TFLOPS | 835 TFLOPS |
| BFLOAT16 Tensor Core2 | 1,979 TFLOPS | 1,671 TFLOPS |
| FP16 Tensor Core2 | 1,979 TFLOPS | 1,671 TFLOPS |
| FP8 Tensor Core2 | 3,958 TFLOPS | 3,341 TFLOPS |
| INT8 Tensor Core2 | 3,958 TFLOPS | 3,341 TFLOPS |
| GPU Memory | 141GB | 141GB |
| GPU Memory Bandwidth | 4.8TB/s | 4.8TB/s |
| Decoders | 7 NVDEC 7 JPEG |
7 NVDEC 7 JPEG |
| Confidential Computing | Supported | Supported |
| Max Thermal Design Power (TDP) | Up to 700W (configurable) | Up to 600W (configurable) |
| Multi-Instance GPUs | Up to 7 MIGs @18GB each | Up to 7 MIGs @16.5GB each |
| Form Factor | SXM | PCIe Dual-slot air-cooled |
| Interconnect | NVIDIA NVLink: 900GB/s PCIe Gen5: 128GB/s |
2- or 4-way NVIDIA NVLink bridge: 900GB/s per GPU PCIe Gen5: 128GB/s |
| Server Options | NVIDIA HGX™ H200 partner and NVIDIA-Certified Systems™ with 4 or 8 GPUs | NVIDIA MGX™ H200 NVL partner and NVIDIA-Certified Systems with up to 8 GPUs |
| NVIDIA AI Enterprise | Add-on | Included |
1. Preliminary specifications. May be subject to change.
2. With sparsity.
HGX H100
| NVIDIA HGX H100 4-GPU | NVIDIA HGX H100 8-GPU | |
|---|---|---|
| FP64 | 134 TFLOPS | 268 TFLOPS |
| FP64 Tensor Core | 268 TFLOPS | 535 TFLOPS |
| FP32 | 268 TFLOPS | 535 TFLOPS |
| TF32 Tensor Core | 3,958 TFLOPS* | 7,915 TFLOPS* |
| FP16 Tensor Core | 7,915 TFLOPS* | 15,830 TFLOPS* |
| FP8 Tensor Core | 15,830 TFLOPs* | 31,662 TFLOPS* |
| INT8 Tensor Core | 15,830 TOPS* | 31,662 TOPS* |
| GPU メモリ | 320GB | 640GB |
| メモリバンド幅 | 13TB/s | 27TB/s |
| NVLink | 対応 | 対応 |

| NVIDIA H100 Tensor Core GPU[PCIe] | |
|---|---|
| GPUアーキテクチャ | Hopper |
| GPUメモリ | 80 GB HBM2e |
| ECC機能 | 対応 |
| メモリバンド幅 | 2 TB/s |
| メモリバス | 5,120 bit |
| Compute Capability | 9 |
| CUDAコア | 14,592 |
| RTコア | 0 |
| Tensorコア | 456 |
| NVLink | 対応 |
| ベースクロック | 1,065 MHz |
| GPU Boost クロック | 1,620 MHz |
| 最大消費電力 | 350 W |
| 補助電源 | PCIe CEM5 16 pin |
| バスインターフェース | PCIe 5.0 × 16 |
| トランジスタ数 | 80 |
| マルチインスタンスGPU | 各10GBで最大7つのMIGS |
| 相互接続 | NVLink:600GB/sPCIe Gen5:128GB/s |

| NVIDIA L40S | |
|---|---|
| GPUアーキテクチャ | NVIDIA Ada Lovelace |
| GPUメモリ | 48 GB GDDR6 |
| メモリバンド幅 | 864 GB/s |
| CUDAコア | 8,176 |
| Tensorコア | 568 |
| RTコア | 142 |
| NVLink | 非対応 |
| 冷却方式 | パッシブ |
| MIGサポート | なし |
| 補助電源コネクタ | PCI Express CEM5 16pin電源コネクタ×1 |
| 最大消費電力 | 350 W |
| サイズ | 高さ 111.15 mm 長さ 267.70 mm 2スロットサイズ(* ブラケット含まず) |
| 保証期間 | 3年間 センドバック方式 |

| NVIDIA L40 [PCIe] | |
|---|---|
| GPUアーキテクチャ | Ada Lovelace |
| GPUメモリ | 48 GB GDDR6 |
| ECC機能 | 対応 |
| メモリバンド幅 | 864 GB/s |
| メモリバス | 384 bit |
| Compute Capability | 8.9 |
| CUDAコア | 18,176 |
| RTコア | 142 |
| Tensorコア | 568 |
| NVLink | 非対応 |
| ベースクロック | 735 MHz |
| GPU Boost クロック | 2,490 MHz |
| 最大消費電力 | 300 W |
| 補助電源 | PCIe CEM5 16 pin |
| バスインターフェース | PCIe 4.0 × 16 |
| トランジスタ数 | 76.3 |
| マルチインスタンスGPU | 非対応 |

| NVIDIA L4 [PCIe] | |
|---|---|
| GPUアーキテクチャ | NVIDIA Ada Lovelace |
| GPUメモリ | 24GB GDDR6 |
| ECC機能 | 対応 |
| メモリバンド幅 | 300 GB/s |
| メモリバス | 192 bit |
| CUDAコア | 7,424 |
| RTコア | 58(第3世代) |
| Tensorコア | 232(第4世代) |
| NVLink | 非対応 |
| 最大消費電力 | 72W |
| 補助電源 | 不要 |
パートナー

関連製品






NVIDIA データセンターGPUをご利用・ご検討のお客様におすすめのソリューション
![]()
ソフトウェア
GPU処理高速化ソリューション
Federator.ai GPU Booster

サーバー(ハードウェア)
Supermicro GPUサーバー製品
VDI環境の基盤やAI・ディープラーニング開発など高い演算能力が必要なワークロードに

サーバー(ハードウェア)
Supermicro 汎用サーバー製品
エンタープライズサーバーアプリケーションのための、汎用エントリーレベルと、ボリューム向けサーバー


