


NVIDIA H100とは?
あらゆるデータ センターにかつてない性能、拡張性、セキュリティを提供し、あらゆるワークロードに対応します。
製品の特長と利点
01
先進のAIトレーニング技術
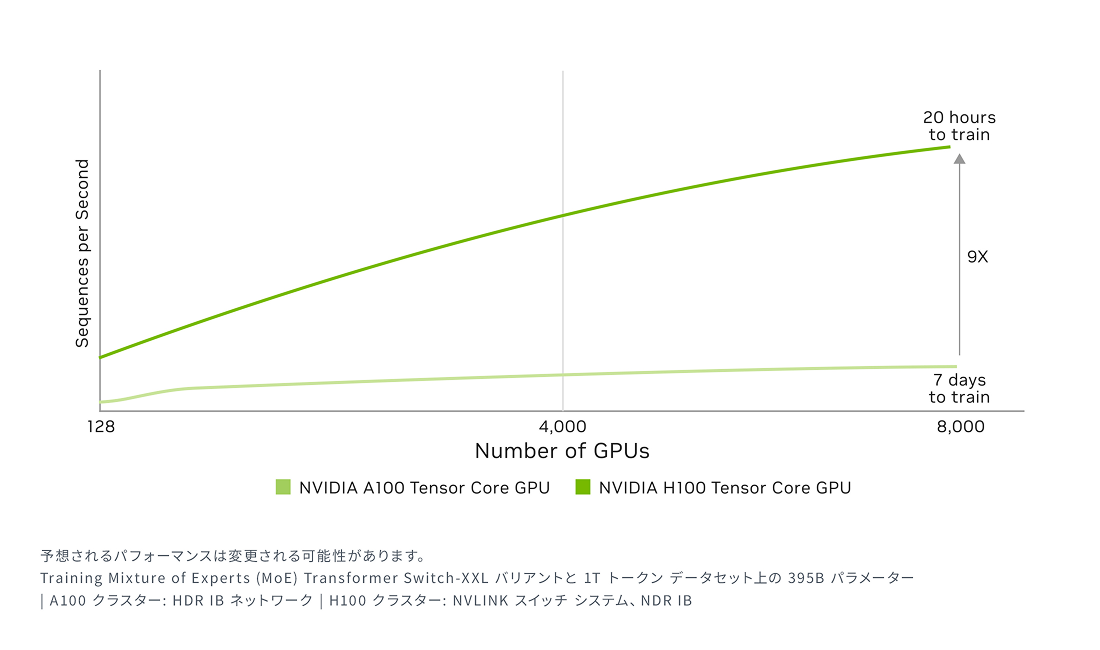
H100は、第4世代のTensorコアとFP8精度で動作するTransformer Engineを搭載し、前世代と比べて混合エキスパート (MoE) モデルのトレーニング速度を最大9倍に向上させます。第4世代NVLinkによるGPU間の毎秒900ギガバイトの高速通信、NVLINK Switch Systemによるノード全体でのGPU通信の高速化、PCIe Gen5、そしてNVIDIA Magnum IO™ソフトウェアが組み合わさることで、小規模なエンタープライズから大規模な統合GPUクラスターまで、効率的なスケーラビリティが実現されます。
データセンター規模でのH100 GPUの導入は、卓越したパフォーマンスを提供し、研究者に次世代のエクサスケール ハイパフォーマンス コンピューティング (HPC) と兆単位パラメーター AI をもたらします。
最大規模のモデルでAIトレーニング性能を最大9倍に
02
リアルタイムのディープラーニング推論
AIは、さまざまなビジネス課題を多様なニューラルネットワークを使って解決します。そのため、優れたAI推論アクセラレータには、最高のパフォーマンスと多様なネットワークを加速するための柔軟性が求められます。
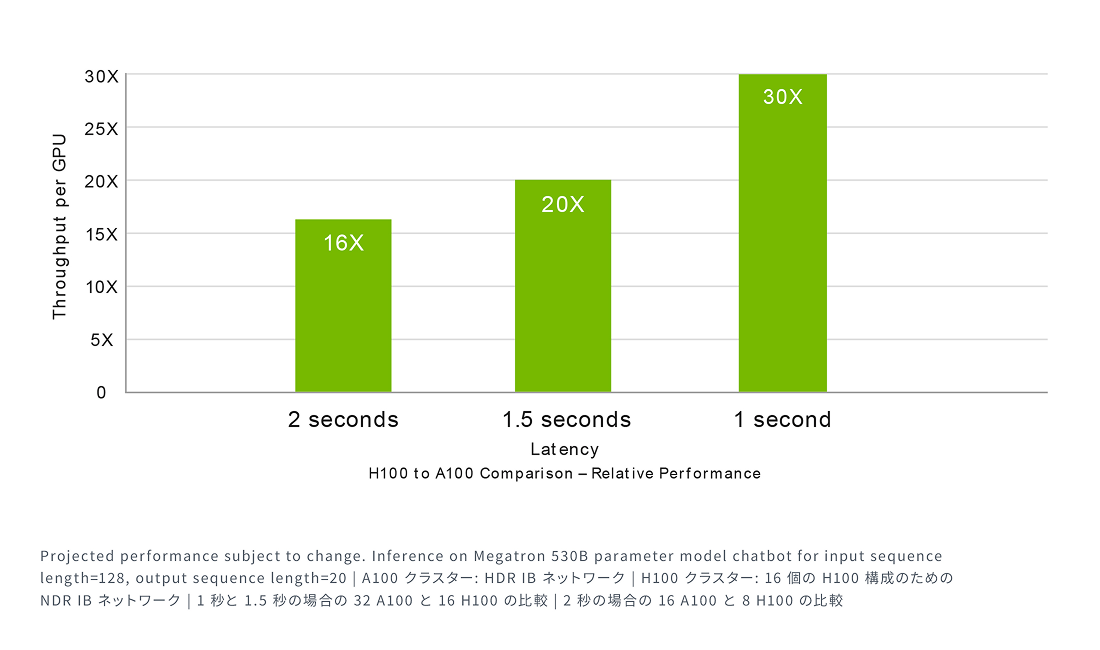
H100は、推論速度を最大30倍に向上させ、遅延を最小限に抑える機能を強化することで、市場をリードするNVIDIAの推論性能をさらに拡大します。第4世代のTensorコアは、FP64、TF32、FP32、FP16、INT8、そして新たにFP8までのあらゆる精度を高速化し、大規模な言語モデルで精度を保ちながらメモリ消費を削減し、性能を向上させます。
最大規模のモデルでAI推論性能を最大30倍に。
Megatronチャットボット推論 (5300億個のパラメーター)
03
エクサスケール ハイパフォーマンスコンピューティング
NVIDIAのデータセンタープラットフォームは、ムーアの法則を超える持続的なパフォーマンス向上を提供します。H100の革新的なAI機能は、HPCとAIのパワーをさらに強化し、科学者や研究者が世界の最重要課題を解決するための発見プロセスを加速させます。
H100は、倍精度Tensorコアの浮動小数点演算(FLOPS)性能を3倍に引き上げ、HPCで60 teraFLOPSのFP64コンピューティングを実現します。AIと融合したHPCアプリケーションでは、H100のTF32精度を活用し、コードの変更なしに単精度行列乗算演算で1 petaFLOPのスループットを達成できます。
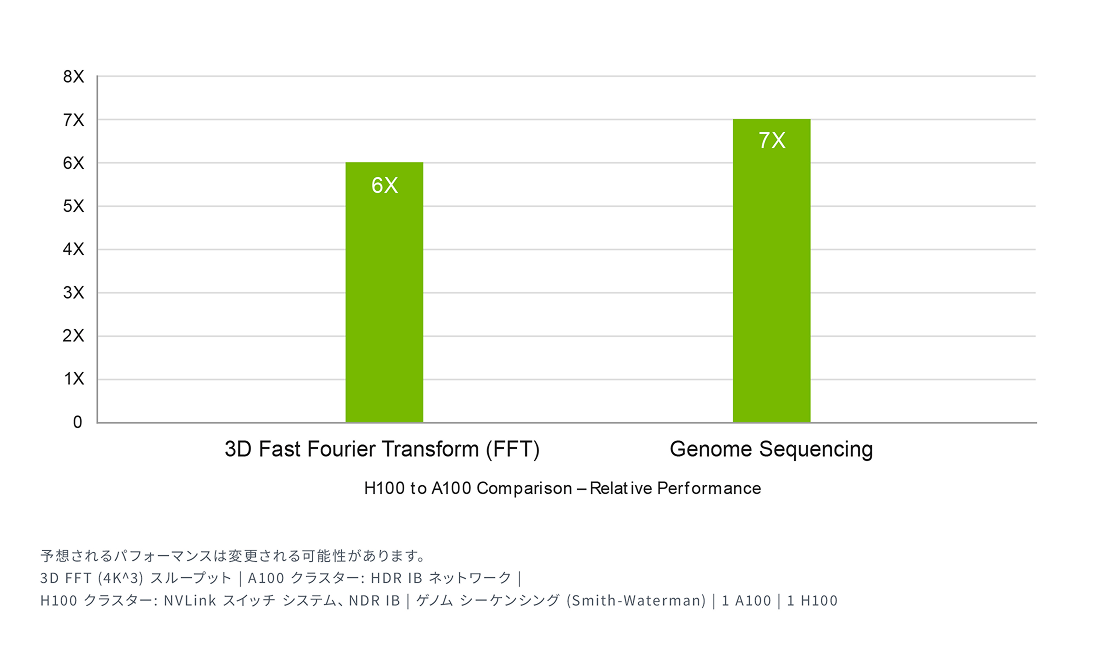
さらに、H100はDPX命令を備え、NVIDIA A100 TensorコアGPUの7倍のパフォーマンスを発揮します。DNAシーケンスアライメント用のSmith-Watermanなどの動的プログラミングアルゴリズムにおいて、従来のデュアルソケットCPUのみのサーバーと比較して40倍の高速化を実現します。
HPCアプリケーションのパフォーマンスが最大7倍に。
04
データ分析の高速化
データ分析は、AIアプリケーションの開発において多くの時間を占める重要なプロセスです。
大規模なデータセットが複数のサーバーに分散されることが多いため、CPUのみの一般的なサーバーによるスケールアウトソリューションでは、スケーラブルなコンピューティングパフォーマンスが不足し、処理が滞ることがあります。
H100を搭載したサーバーは、GPUごとに毎秒3テラバイトのメモリ帯域幅を提供し、NVLinkとNVSwitchを使用することで高いスケーラビリティを実現します。これにより、膨大なデータセットに対する高性能なデータ分析が可能になります。NVIDIA Quantum-2 Infiniband、Magnum IOソフトウェア、GPU加速のSpark 3.0、そしてNVIDIA RAPIDS™と組み合わせることで、NVIDIAデータセンタープラットフォームは、他に類を見ない方法で膨大なワークロードを高速化し、卓越したパフォーマンスと効率性を提供します。
05
企業で効率的に利用
ITマネージャーは、データセンターでのコンピューティングリソースの利用率(ピーク時と平均時の両方)を最大化することを目指します。多くの場合、コンピューティングを動的に再構成し、使用中のワークロードに応じてリソースのサイズを調整します。
H100の第2世代マルチインスタンスGPU(MIG)は、1つのGPUを7つのインスタンスに分割でき、各GPUの利用率を最大化します。コンフィデンシャルコンピューティング対応のH100は、エンドツーエンドの安全なマルチテナント利用を可能にし、クラウドサービスプロバイダー(CSP)環境に最適です。
H100とMIGを活用することで、インフラストラクチャ管理者はGPUアクセラレーテッドインフラストラクチャを標準化しつつ、GPUリソースを非常に細かくプロビジョニングできます。適切な量のアクセラレーテッドコンピューティングを安全に開発者に提供し、GPUリソースの利用を最適化します。
06
コンフィデンシャル コンピューティングを内蔵
現在のコンフィデンシャルコンピューティングソリューションはCPUベースが主流ですが、AIやHPCなどの大量の計算処理が必要なワークロードには不十分です。NVIDIAコンフィデンシャルコンピューティングは、NVIDIA Hopper™アーキテクチャに組み込まれたセキュリティ機能です。これにより、H100はコンフィデンシャルコンピューティング機能を持つ世界初のアクセラレータとなりました。ユーザーは、データとアプリケーションの機密性と完全性を保護しながら、H100 GPUの卓越した高速化を利用できます。
H100は、ハードウェアベースのTEE(Trusted Execution Environment/信頼できる実行環境)を提供し、単一のH100 GPU、複数のH100 GPUが配置されたノード、または個々のMIGインスタンス内で実行されるワークロード全体をセキュアに保護し、隔離します。GPUで高速化されるアプリケーションは、変更なしでTEE内で実行でき、分割する必要もありません。ユーザーは、AIおよびHPCのためのNVIDIAソフトウェアのパワーと、NVIDIAコンフィデンシャルコンピューティングによるハードウェアRoT(Root of Trust/信頼の起点)のセキュリティを組み合わせることができます。
07
大規模なAIとHPCのための比類のないパフォーマンス
Hopper TensorコアGPUは、NVIDIA Grace Hopper CPU+GPUアーキテクチャの力を活かし、テラバイト規模のアクセラレーテッドコンピューティングを実現します。これにより、大規模モデルのAIとHPCで10倍のパフォーマンス向上が達成されます。NVIDIA Grace CPUはArm®アーキテクチャの柔軟性を活用し、アクセラレーテッドコンピューティングのためにCPUとサーバーのアーキテクチャをゼロから設計することが可能です。Hopper GPUは、NVIDIAの超高速チップ間相互接続を通じてGrace CPUとペアリングされ、毎秒900GBの帯域幅を提供し、PCIe Gen5と比較して7倍の速さを実現します。
この革新的な設計により、現行で最速のサーバーと比べて、GPUへの合計システムメモリ帯域幅が最大30倍に増加します。結果として、パフォーマンスが最大10倍向上し、テラバイト単位のデータをアプリケーションで効率的に処理できます。
製品の活用例

AI開発

ディープラーニング

データセンター
製品スペック
| フォーム ファクター | H100 SXM | H100 PCIe | H100 NVL¹ |
|---|---|---|---|
| FP64 | 34 teraFLOPS | 26 teraFLOPS | 68 teraFLOPs |
| FP64 Tensor コア | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| FP32 | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| TF32 Tensor コア | 989 teraFLOPS² | 756 teraFLOPS² | 1,979 teraFLOPs² |
| BFLOAT16 Tensor コア | 1,979 teraFLOPS² | 1,513 teraFLOPS² | 3,958 teraFLOPs² |
| FP16 Tensor コア | 1,979 TFLOPS² | 1,513 teraFLOPS² | 3,958 teraFLOPs² |
| FP8 Tensor コア | 3,958 TFLOPS² | 3,026 teraFLOPS² | 7,916 teraFLOPs² |
| INT8 Tensor コア | 3,958 TFLOPS² | 3,026 TOPS² | 7,916 TOPS² |
| GPU メモリ | 80GB | 80GB | 188GB |
| GPU メモリ帯域幅 | 3.35TB/秒 | 2TB/秒 | 7.8TB/秒³ |
| デコーダー | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 14 NVDEC 14 JPEG |
| 最大熱設計電力 (TDP) | 最大700W(構成可能) | 300–350W(構成可能) | 2x 350-400W(構成可能) |
| マルチインスタンス GPU | 最大7個のMIG @10GB | 各12GBの最大14のMIG | |
| フォーム ファクター | SXM | PCIe デュアルスロット空冷 | 2x PCIe デュアルスロット空冷 |
| 相互接続 | NVLink: 900GB/秒 PCIe Gen5: 128GB/秒 | NVLINK: 600GB/秒 PCIe Gen5: 128GB/秒 | NVLink: 600GB/秒 PCIe Gen5: 128GB/秒 |
| サーバー オプション | 4 または 16 GPU 搭載の NVIDIA HGX™ H100 パートナーおよび NVIDIA-Certified Systems™ 8 GPU 搭載の NVIDIA DGX™ H100 | 1~8 GPU 搭載のパートナーおよび NVIDIA Certified Systems™ | 2-4 組のパートナーおよび NVIDIA Certified Systems™ |
| NVIDIA AI Enterprise | アドオン | 含む | 含む |
1.参考仕様。仕様は変更される場合があります。H100 NVL PCIe カード 2 枚と NVLink Bridge を組み合わせた場合の仕様です。
2.疎性あり
3.HBM 帯域幅の総計
製品のよくある質問
GPUサーバーはNVIDIA認定を受けていますか?
はい。NVIDIA認定済みのGPUサーバーを提供しています。
サーバーのサイジングに協力していただくことは可能ですか?
はい。用途や希望スペック、ご予算などをヒアリングさせていただき、最適なものを提案いたします。
スペックの細かなカスタマイズは可能ですか?
はい。ご希望があればCPU、メモリー、ストレージ、ネットワークなどを細かくカスタマイズ可能です。サーバー本体や搭載するGPUにより推奨構成があるため、まずはご希望をお伺いさせていただきながらご提案いたします。
価格について教えてください。
構成に応じてパーツが変わるため都度お見積りいたします。ご相談ください。
GPUDirect RDMAは利用できますか?
GPUDirect RDMAを利用可能なサーバーもございます。必要要件がありますのでまずはご希望などをお聞かせください。
パートナー

保証・サポート
導入時のサポート
HW選定のご相談から組み立て、ラッキングまでサポートいたします。 ご要望によりOS導入・初期設定・各種ソリューションの構築も対応可能です。 記載の無い要件であっても対応可能なケースがございます。








